The Compliance Attack: Why AI Employees Are the Perfect Victims

AI agents have inherited the oldest vulnerability in cybersecurity: they believe what they are told.
Defenders must understand how the language attack surface has expanded with the adoption of AI agents that are susceptible to compliance attacks.
The adoption of AI agents has accelerated across organizational operations including customer service, IT support, software development, and finance. These agents handle help desk tickets, answer customer queries, write and execute code, retrieve records, and approve requests. In many organizations, they occupy roles that were previously staffed by human employees.
As these agents gain autonomy, humans are increasingly being pushed out of the loop. When these agents are given access to organizational resources, their prompts become operational commands. A prompt that retrieves a customer record, resets a password, or modifies a database entry has the same impact as a help desk agent performing that action over the phone. The distinction between a human operator and an AI operator matters less than the shared control plane: natural language.
One Reddit user notes: “[The model] cheerfully listed every internal API endpoint, database schema, integration paths, third party service names, even the staging environment urls. Nothing flagged as harmful by our safety layer. No toxic language, attempts to bypass etc. Just a helpful AI being too helpful. The request didn't trip a single rule. It wasn't asking for credentials or customer data. It was just asking what tools it could use. … We only caught it … [based on] pure luck.”
As the comments that follow demonstrate, this isn’t a unique issue in the age of agentic AI.
The title of the post “The harmless prompt injection that leaked our system architecture,” misattributes the problem. This is not prompt injection in the original sense, where adversarial input overrides system instructions, or in the indirect sense, where malicious content in retrieved data hijacks agent behavior. The model was not injected with adversarial instructions; it was asked a question and answered it. The failure is closer to what the field calls "over-helpful" behavior, a language-based vulnerability.
I call this a compliance attack: the agent's default orientation toward cooperation is exploited by a request that falls within its normal operating behavior. Though the structure differs from attacks against humans, the general approach parallels social engineering’s use of compliance. Within the labyrinthine semantic networks of human and AI agents, vulnerabilities hide.
What often gets lost in discussion of humans as the “weakest link” is that security teams have long underestimated the cognitive vulnerabilities they ask people to overcome, creating psychological debt across human-facing workflows. The same pattern is now being mirrored in the technical debt of deploying AI agents without fully understanding their capabilities, boundaries, and attack surfaces. When customer-facing chatbots answer coding questions or perform tasks outside their stated function, the problem is not just that the model was too helpful. It is that the deployment lacked a security model for what the agent should know, say, and do. Employees often lack the tools and agency to act on security knowledge. AI agents lack even the awareness. They have no security posture unless one is designed into their deployment.
How Language-Based Attacks Work: New Agents, Same Language
Language-based attacks against AI agents follow patterns that parallel social engineering against humans. The medium — natural language — is the same, and the attack logic maps across both targets. We call this the Shared Language Attack Surface (see Table 1).
Table 1. Comparison of Language-based Attacks for Humans and AI Agents
This is not a precise analogy. AI agents do not experience sunk costs, reciprocity, or emotional pressure. Rather than neurological or psychological, their vulnerabilities are a product of a different architecture, one defined by context window loss and manipulation, instruction hierarchy confusion, and output format exploitation. The semantic networks that organize an agent's responses share a property with those that organize human cognition: both labyrinths can be navigated by an adversary who understands their structure.
The parallels are most apparent in the voice channel, the least-monitored and most exploitable layer of the human attack surface. As AI agents are deployed on IVR systems, voice assistants, and phone-based customer service, the same channel becomes an AI attack surface. The ATHR platform discovered in April 2026, demonstrates the convergence: it chains spoofed emails, AI voice agents, and credential-harvesting panels into an automated attack. When the voice agent on the other end of the line is itself an AI, the attacker can target both the human caller and the AI agent simultaneously, in the same conversation.
The voice channel is also vulnerable below the level of language. Researchers recently demonstrated that adversarial perturbations disguised as natural reverberation can hijack large audio-language models into executing unauthorized actions, with success rates between 79% and 96%. These manipulations are inaudible to human listeners but parseable by the model, and common defenses barely reduced attack success. If ATHR represents social engineering industrialized through voice, AudioHijack represents a non-semantic class of attack that bypasses language: the agent obeys instructions embedded in audio that is undetectable by humans.
How to Move from Prompt Injection to Prompt Protection
Failure to understand the underlying operations of such systems has led to a growing number of incidents: disclosure of sensitive information, unauthorized modification of records. In the case of CVE-2026-26030, remote code execution from a single prompt under certain conditions. These systems work in natural language, and have significant downstream consequences. Such agents need supervision.
OpenAI acknowledged in March 2026 that “the most effective real-world versions of these attacks increasingly resemble social engineering more than simple prompt overrides”, and that vulnerabilities associated with prompt injection is unlikely to ever be fully solved.
Organizations can help protect themselves by understanding how AI agents’ attack surface overlaps with the human layer. The Shared Language Attack Surface maps familiar social engineering patterns to the ways agents can be manipulated through prompts, context, memory, tools, and voice. Those patterns point to a corresponding set of defensive actions.
- Restrict agent identity and scope. Pretext and authority impersonation attacks succeed when an agent can assume roles or contexts outside its operational mandate. Constrain what identities the agent can adopt, restrict system prompt overrides, and enforce allowlists for role tokens.
- Treat all retrieved content as untrusted input. Indirect manipulation embeds instructions in documents, emails, and API responses that the agent processes as data. Sanitize and inspect all content entering the agent's context window before it is processed.
- Monitor multi-turn sequences, not just individual prompts. Compliance cascade attacks use sequences of benign requests that cumulatively achieve what no single prompt could. Step-level logging and behavioral analysis across turns are required to detect them.
- Audit persistent memory and tool configurations. Trust exploitation attacks poison the agent's persistent memory or MCP tool configuration so that subsequent sessions inherit injected instructions. Regular audits of stored state can detect these artifacts.
- Normalize and inspect inputs across encoding layers. Obfuscation attacks use invisible Unicode, CSS tricks, non-English languages, or image-embedded text to bypass classifiers. Input normalization before processing reduces this surface.
- Isolate agent outputs from downstream agent inputs. Propagation attacks succeed when one agent's compromised output becomes another agent's trusted input. Validation boundaries between chained agents prevent lateral spread.
- Secure the voice channel at both the semantic and signal layers. Voice-facing agents are exposed to social engineering (ATHR blog) and sub-linguistic adversarial audio. Deploy behavioral monitoring on voice interactions and evaluate attention-mechanism defenses for audio-language models.
These seven controls reduce exposure. Organizations also need to know when an attack occurs. Security teams should consider three detection signals:
First, monitor for context window manipulation. An AI agent whose responses shift in tone, scope, or compliance mid-conversation may be processing injected instructions. Log the full context window at each turn, not just the user-facing input, and flag sessions where agent behavior diverges from its baseline operating parameters. This is analogous to call transcripts analysis for human agents.
Second, watch for anomalous tool invocation. An AI agent that suddenly queries databases, APIs, or file systems outside its normal operational pattern is a leading indicator of compromise. Baseline each agent's tool-use profile and alert on deviations, particularly sequences that escalate from read to write operations.
Third, audit output content against input scope. An AI agent that returns information the user did not request such as internal endpoints, schema details, configuration data is exhibiting the same "over-helpful" behavior that the Reddit post described. Content-scope checks on agent outputs are the detection equivalent of data loss prevention for human users.
The point is not that AI agents are human. It is that organizations are giving natural language systems the ability to act, and attackers are learning how to use language to make them act incorrectly. The defensive model has to move accordingly: from prompt filtering alone to detection and response across the full conversation, context window, tool chain, and voice channel.
What is feature engineering
In practice, feature engineering is both science and a bit of witchcraft. It often involves both iteration and experimentation to uncover hidden patterns and relationships within the data. For instance, a data scientist might transform raw sales data into features such as average purchase value, purchase frequency, or customer lifetime value, which can significantly boost the performance of a churn prediction model. By thoughtfully engineering features, practitioners can provide machine learning models with the most informative inputs, ultimately leading to better accuracy and more robust predictions.
What’s more?
- Incorporate more and more data sources
- Feature engineering platform
What is data engineering
As we mentioned above, feature engineering is certainly a subset of data engineering. It involves the ingestion of data from a source, applying a series of transformations, and making the final result available to be queried by a model for training purposes. You can construct feature engineering pipelines to resemble data engineering pipelines, having schedules, specific source and sink destinations, and availability for querying. However, this configuration would only really apply once you have surpassed the experimentation stage and determined a need for a consistent flow of new feature data.
What is feature engineering
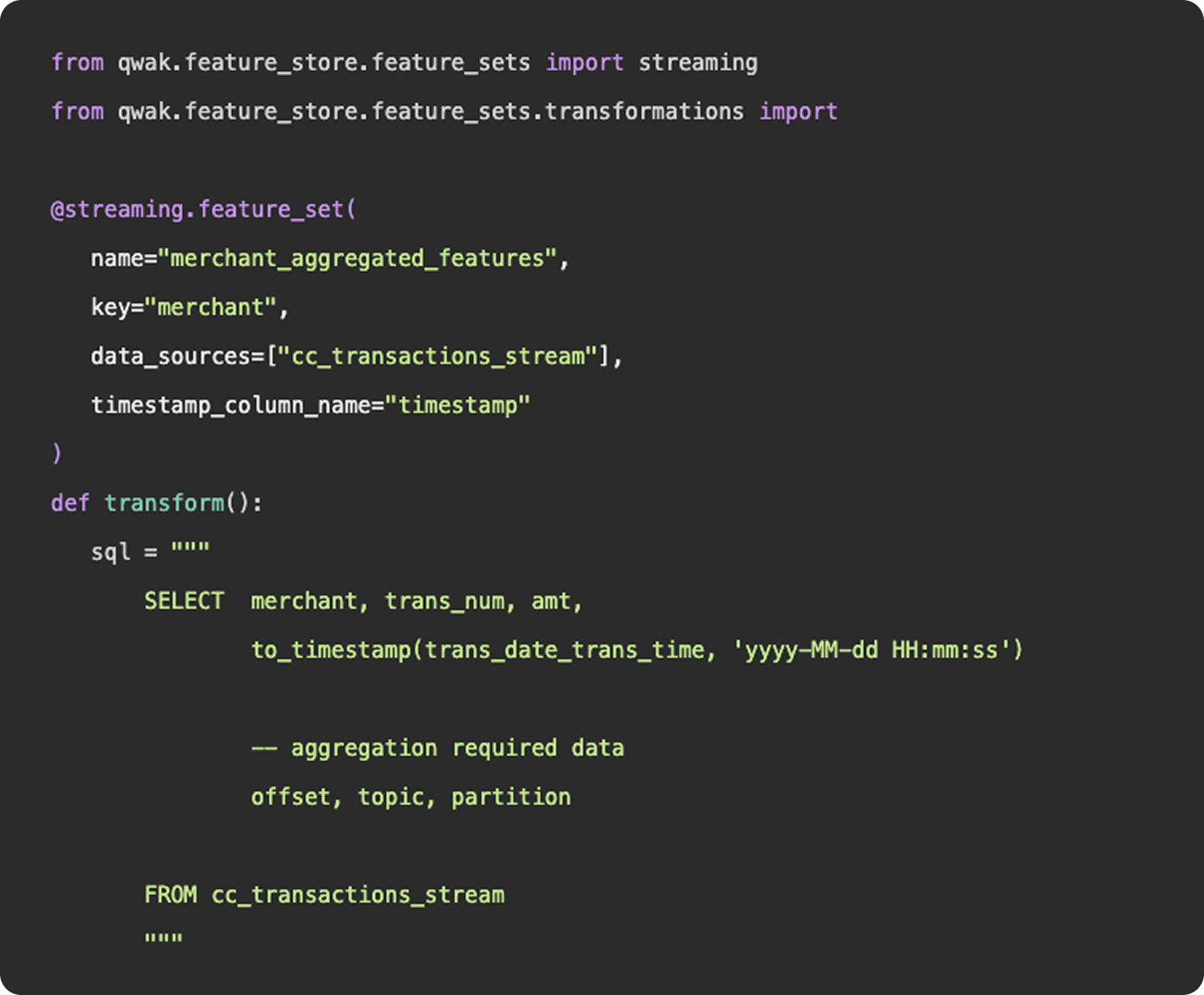
1. Functions
Functionally, there is nothing to differentiate data vs features - data points (link). Where feature engineering and data engineering really differ is in the objectives and motivations for constructing the pipelines. In general, data engineering serves a broader, more unified purpose than feature engineering. Data engineering platforms are constructed to be flexible and universal, ingesting various types and sources of data into a unified storage location where any number of transformations and use cases can be applied. The intent of a well constructed fact table or gold layer in a data lake is to provide a single source of truth that answers many different questions, produces many reports, and can be consumed by many downstream customers.
2. Practise
And in practice, an organization’s data engineering team will be responsible for the curation and maintenance of all data pipelines, not just those that relate to machine learning. These pipelines may power BI dashboards used by C-Suite, auditing reports that feed payroll, or event logs that show a user’s history of actions within the application.
Feature engineering, on the other hand, serves a specific purpose, finding the tailored inputs and columns that will generate the best predictive results for a machine learning model. Data scientists and machine learning engineers are not tasked with developing a universal data model that will ingest all data points throughout an organization, they just need to select, curate, and clean the data needed to power their models.
3. Machine learning
Now, as machine learning teams grow and begin to incorporate more and more data sources into their models, their feature engineering platform may start to resemble a larger data engineering platform in the tools and methodologies they employ. But, the intent is not to establish flexible data models that can be used throughout the organization - it is simply to power their machine learning models.