Stopping Social Engineering


Social engineering is a scourge on society.
It’s the number one breach vector, and is only going to get worse as AI-powered attackers mount relentless attacks on our people. Our industry's response? “Blame and train” - Blame the victims and make them take more training. We started Humanix to end that cycle. Using conversational AI trained on the psychology of manipulation, we detect social engineering attacks as they happen—across voice, chat, and email—giving security teams the same detection and response capabilities for human-targeted attacks that they have for malware. At Humanix, we're here to stop social engineering.
Social engineering has gone from being a parlor trick to the primary enterprise breach vector. Enterprises lose billions every year as attackers exploit the most important asset any organization has - their people.
Our response as an industry has been anemic at best. People are hard. Language is even harder. So rather than try and stop social engineering, the industry has chosen to delegate the problem back to the very people we’re responsible for protecting. We call it security awareness training, but what we’re really doing is blaming the victim. When attackers are successful at victimizing our people, we punish our people with ever more training.
There’s a better way.
In the early days of the company, a CISO friend shared with me the audio recording of the Scattered Spider social engineering attack on the help desk of a major hospitality corporation. The attackers already had a ton of intel on the company, but they had to defeat MFA, and the help desk was the way to do it. One phone call to some poor agent trying to be helpful led to a $100m loss event. As I listened to the recording, I found myself wanting to shout out loud. “It’s a scam! He’s not who he says he is!” It was maddening, but also led to a moment of clarity: There’s signal in those interpersonal interactions - meaning the tactics and techniques that make up a social engineering attack are detectable in natural language. Manipulation, pressure, ignorance, policy evasion. Is it reasonable to expect the poor help desk agent to get that right 100% of the time? No. Can we train software and large language models to detect these attacks? Yes we can.
Social engineering is an attack class like any other. Instead of zero-days or buffer overflows, it uses natural language. Defeating this class of attacks requires a new kind of detection and response product - human threat detection and response. Large language models and conversational AI now make that possible at scale. If attackers are going to exploit AI to super-charge their social engineering, we must fight back with AI to protect our people.
We can’t do this alone. We’re on this journey with some of the most talented cybersecurity investors and practitioners in the business: Ed Sim at boldstart who led our Seed round, and Asad Khaliq at Acrew Capital who led our Series A, joined by Evolution Equity, Tokyo Black, DNX Ventures, and many more angels and cybersecurity experts. Combined, we’ve raised $18m to fuel our growth and development. More than that, we’re building a group of people passionate about truly solving the social engineering challenge.
At Humanix, we believe we can protect people, not punish them. We believe that we can detect and respond to natural language attacks, just as we do every other attack class that faces the enterprise. We believe we can stop social engineering.
What is feature engineering
In practice, feature engineering is both science and a bit of witchcraft. It often involves both iteration and experimentation to uncover hidden patterns and relationships within the data. For instance, a data scientist might transform raw sales data into features such as average purchase value, purchase frequency, or customer lifetime value, which can significantly boost the performance of a churn prediction model. By thoughtfully engineering features, practitioners can provide machine learning models with the most informative inputs, ultimately leading to better accuracy and more robust predictions.
What’s more?
- Incorporate more and more data sources
- Feature engineering platform
What is data engineering
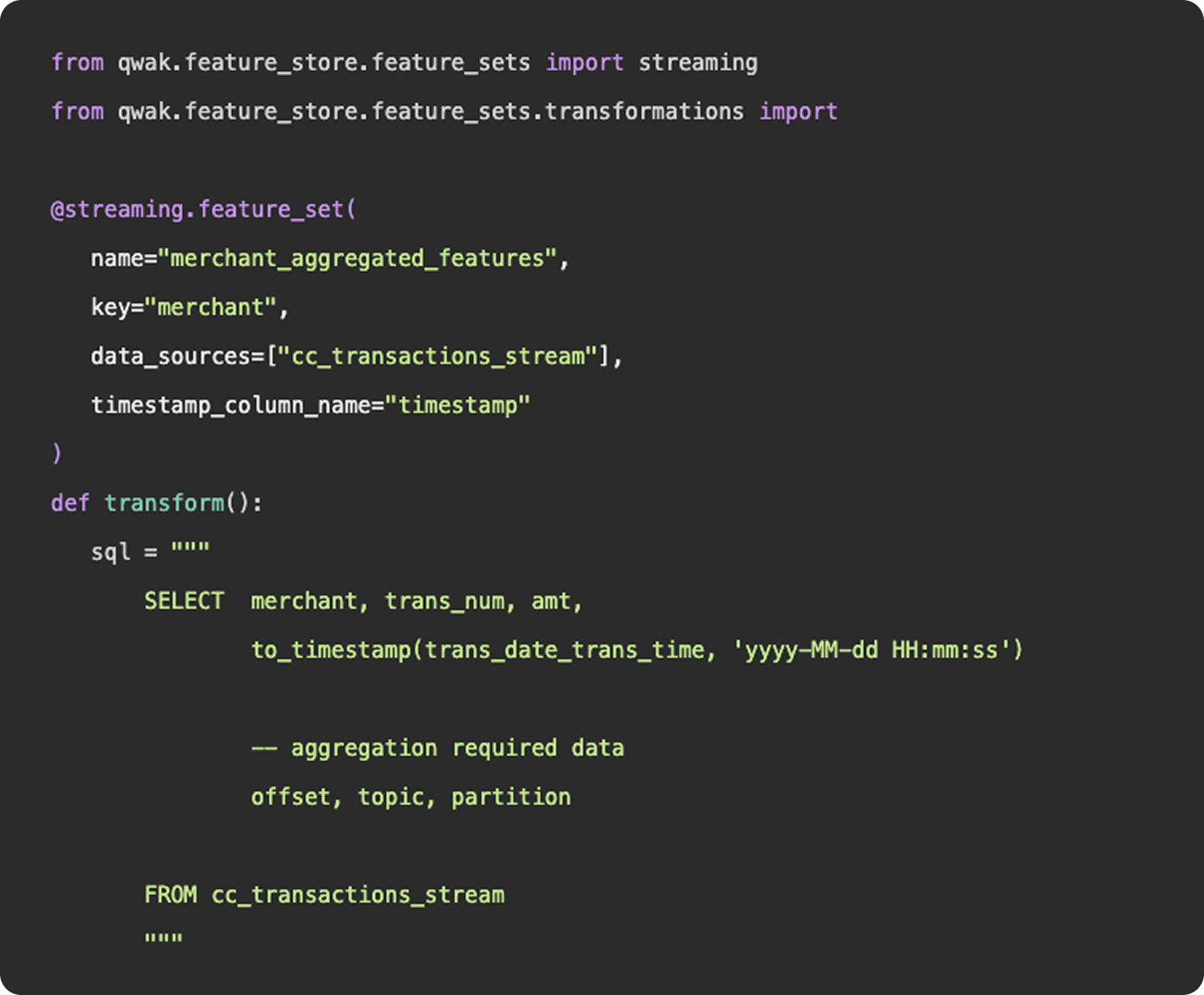
As we mentioned above, feature engineering is certainly a subset of data engineering. It involves the ingestion of data from a source, applying a series of transformations, and making the final result available to be queried by a model for training purposes. You can construct feature engineering pipelines to resemble data engineering pipelines, having schedules, specific source and sink destinations, and availability for querying. However, this configuration would only really apply once you have surpassed the experimentation stage and determined a need for a consistent flow of new feature data.
What is feature engineering
1. Functions
Functionally, there is nothing to differentiate data vs features - data points (link). Where feature engineering and data engineering really differ is in the objectives and motivations for constructing the pipelines. In general, data engineering serves a broader, more unified purpose than feature engineering. Data engineering platforms are constructed to be flexible and universal, ingesting various types and sources of data into a unified storage location where any number of transformations and use cases can be applied. The intent of a well constructed fact table or gold layer in a data lake is to provide a single source of truth that answers many different questions, produces many reports, and can be consumed by many downstream customers.
2. Practise
And in practice, an organization’s data engineering team will be responsible for the curation and maintenance of all data pipelines, not just those that relate to machine learning. These pipelines may power BI dashboards used by C-Suite, auditing reports that feed payroll, or event logs that show a user’s history of actions within the application.
Feature engineering, on the other hand, serves a specific purpose, finding the tailored inputs and columns that will generate the best predictive results for a machine learning model. Data scientists and machine learning engineers are not tasked with developing a universal data model that will ingest all data points throughout an organization, they just need to select, curate, and clean the data needed to power their models.
3. Machine learning
Now, as machine learning teams grow and begin to incorporate more and more data sources into their models, their feature engineering platform may start to resemble a larger data engineering platform in the tools and methodologies they employ. But, the intent is not to establish flexible data models that can be used throughout the organization - it is simply to power their machine learning models.
.png)