Making Social Engineering Visible: Four Structural Problems in Organizations


Defenders cannot see social engineering until it has succeeded.
The gap operates at four layers: signals the detection stack does not capture, schemas that cannot classify what it does capture, sectors that do not share what they learn, and adversary methods that organizations do not understand. This is the Four T Problem.
A villain in an 80s movie once noted that if “[a] man can’t see, he can’t fight.” Defenders have spent three decades building a detection stack for a different kind of threat. Cybersecurity has increased visibility into the operations and vulnerabilities of technical systems. SIEMs correlate packets, processes, and payloads in milliseconds. AI-assisted platforms analyze behavioral signals across networks, endpoints, and identity layers.
The sustained increase in high-profile attacks against organizations with mature security infrastructure makes one thing clear: social engineering is not visible until after it has succeeded.
In 2024–2025 Crowdstrike reported a 442 % increase in vishing between the first and second halves of the year. Keepnet has also reported that 70% of organizations had staff who shared sensitive information during simulated vishing calls. The number of real successes is often unknown unless organizations disclose it.
Attackers are playing a numbers game. Defenders are losing it. Adversaries are now pooling their resources, specializing and outsourcing to third-parties. Where there was once a human bottleneck, AI has changed the equation. AI voice cloning and LLM script generation have started to industrialize, allowing attackers to run more sophisticated campaigns in parallel.
This is a structural asymmetry: an attacker only needs one success out of a hundred attempts. Defenders need every call resolved quickly and correctly every time. The margin of error has narrowed. By the time a vishing call appears in an incident report, the credential is already lost, the system is already compromised, the data is already exfiltrated.
Threats You Don’t See
Social engineering is unobservable using the tools, models, and mental frameworks CISOs rely on. It hides in the ambiguity of language, in the normality of social interaction, and in the jagged edges of imperfect workflows.
Whether an employee works in a growing SME, a large multinational with regular staff turnover, or remotely, it is increasingly difficult to know their colleagues. A typical employee anchors their knowledge on their immediate co-workers, supervisor, and the names of a few executives. They are removed from the rest of the organization around them. Research suggests that we can only reliably track about 150 people (’Dunbar’s Number’). A help desk agent responsible for supporting a 50,000-person enterprise cannot realistically be expected to know each caller. Identity can only be verified by proxy: through caller IDs, org charts, verification apps, and internal jargon. There is plenty of space to lose people between the cracks.
The size of organizations and the limitations of human social processing give attackers an advantage: people simplify. Agents handle large volumes by narrowing their attention to a small set of cues. If they didn’t, they couldn’t resolve their tickets. Adversaries exploit this inattentional blindness.
The detection gap is apparent across four layers: what organizations can see, how they categorize what they see, whether they share it, and how well they understand adversary methods.
The Four Ts: Why Social Engineering Stays Invisible
Social engineering remains invisible because the cognitive, social, and institutional infrastructure inside organizations is not tuned to detect it. I call this the Four T Problem: Telemetry, Taxonomy, Transparency, and Techniques. Telemetry defines the observable signals available from organizational tooling. Taxonomy defines what a social engineering attack looks like at each stage of a call or email. Transparency defines whether what one organization learns about an attack reaches the others targeted by the same playbook. Techniques are the specific adversary behaviors those signals must distinguish.
Each of these has developed independently, despite their obvious dependencies. Without telemetry, attacks are implicit, unverifiable, and undocumented, leaving no record of what occurred and when. Without a taxonomy, there is no schema to classify incidents and no shared language to communicate them within or outside the organization. Without transparency, each organization must learn the same playbook through trial and error with their own breaches. Without operationalized techniques, the reasons why social engineering succeeds remain obscure, employee training remains anchored in general awareness rather than specific recognizable attack patterns, and the human attack surface remains undefended.
When these four are absent or misaligned, they create a systemic detection gap. Adversaries exploit it.
1. Missing Telemetry
Visibility requires that detection systems register the relevant cues of human communication: which cues are presented, when they appear, and what they indicate.
MITRE ATT&CK has formalized voice phishing as T1566.004, but most organizations have no log source mapped to it. Email security has three decades of sensor development behind it. Voice has little. The vendor landscape for vishing simulation remains years behind email phishing tooling, producing awareness that quickly fades. These approaches do not produce behavioral scoring, SIEM-compatible output, or measurable baselines that can assess the efficacy of defense.
Despite post-breach awareness of vishing calls, social engineering attacks leave only vague traces. Call center infrastructure produces metadata: ANI/DNIS records, SIP headers, CDR timestamps, and call durations. These signals are not integrated. These fields are not associated with MFA approval events, password reset tickets, or privileged access in any actionable way. What data is available is rarely connected.
UEBA was a promising approach. It offered to look beneath the numbers and find human patterns. But it has not delivered. Baselines are difficult to establish and calibrate, and call-level behavioral context is not preserved across events.
2. Missing Taxonomies
T1566.004 is a starting point, not a detection framework. It is comprehensive at the cost of nuance. By adopting it, organizations can distinguish and communicate about broad classes of events. It is not adapted to the precision needed to detect social engineering. It contains no conditional logic, no call-stage structure, and no mechanism to explain whyan attack succeeded. We can’t blame this framework or its creators, it was not designed to provide explanation.
Risk frameworks such as NIST CSF and FAIR sketch the stages of an attack and the available technology. They provide visibility into the defender stack and a vocabulary for risk discussions, but they do not describe the conversational mechanics of what makes a social engineering call compelling.
An operational social engineering taxonomy would map cognitive and behavioral processes to call phases: creating pretexts, target elicitation, initial and subsequent requests, and exit. Each phase is defined by specific behavioral indicators that obscure intentions and promote compliance in the help desk agent. Each also creates observables: agent ticket modification, password resets, and MFA bypass approvals. When calls are recorded, the language used from start to finish is also available as evidence. The evidence is there. Defenders just need to know what it looks like.
Defenders cannot describe with operational precision what they are looking for. They cannot communicate these tactics and techniques to peer organizations or advisory bodies. That makes building detection logic impractical and leaves training anchored in general awareness rather than specific, recognizable attack patterns.
3. Missing Transparency
Telemetry and taxonomy let an organization see and classify what is happening on its own networks. Transparency determines whether that knowledge reaches other organizations, security professionals, and regulators facing the same playbook.
In July 2025, Marks and Spencer chairman Archie Norman told a UK parliamentary committee that: "quite a large number of cyber attacks never get reported" and added that "we have reason to believe there have been two major cyber attacks on large British companies in the last four months which have gone unreported. We think that's a big deficit in our knowledge as to what's happening."
Two breaches Norman believed to be major had occurred, sector peers were unaware, and the rest of the industry was operating without that intelligence. The British Library took the opposite path, publishing an 18-page incident review in March 2024 explicitly so other institutions could learn from it. That kind of disclosure is the exception. Even then, the report could only describe the access vector by inference. They note:
“The most likely source of the attack is … compromise of privileged account credentials, possibly via a phishing or spear-phishing attack or a brute force attack”.
The British Library could not reconstruct what happened. While voluntary transparency exists, the evidence that needs to be shared often does not.
The transparency gap isn’t simply about regulatory requirements and format, it also extends to credibility. Organizations often do not want to acknowledge that they have been compromised. Nor do they want to admit that they do not understand why the breach happened. Simple explanations are preferred over uncertainty. But honesty about uncertainty is what the sector needs.
4. Missing Technique Awareness
There is a more fundamental issue that underlies the other three: organizations have a limited understanding of how social engineering operates at the cognitive and interpersonal level. Taxonomies and risk assessment frameworks do not address how adversaries operate at each layer of the cognitive stack. They fail to define the cognitive stack within each organization.
Existing cognitive attack taxonomies in the literature are mostly descriptive lists. Cialdini's six principles of influence, the Unified Social Engineering Taxonomy (USET), Gragg's multi-level defense model, and the Cognitive Security Institute’s Cognitive Attack Taxonomy each provide granularity that MITRE does not. Understanding these frameworks provides limited situational awareness for the help desk agent, SOC analyst, or CISO. Keeping them in mind during an attack or a post-incident review is unrealistic.
How Social Engineering Bypasses Human Firewalls
Effective social engineering blends three primary processes: deception, persuasion, and coercion.
Since Darwin, researchers have recognized that humans are caught in an evolutionary arms race. Effective communication requires that we generate and detect social cues accurately. Some individuals can discriminate legitimate from illegitimate emotions better than others. This requires emotional intelligence and social competence. Other individuals produce emotional displays that look genuine and suppress the expression of emotions they do not want revealed. These individuals have an advantage in deception.
A simple model of cognition holds that we use reflective thinking when presented with a new situation and default to an automatic system when something or someone looks familiar. Most of us operate as ‘cognitive misers’ whenever possible. This saves us mental effort and lets us focus on new or more difficult tasks.
The art of human hacking uses this knowledge, making the unfamiliar familiar. Making an attack appear like a typical business transaction. By presenting typical social cues, the attacker shifts the target into automatic mode and promotes reliance on social scripts. Adversaries use the script to lead the victim to the target of their compliance.
Within the ambiguity of language, half-answers to questions can hide problematic responses. The tendency to fill-in-the-blanks with our prior knowledge of what people typically say and do can obscure unverifiable answers, lack of knowledge of organizational processes, and lack of access to standard methods of access control.
There is widespread agreement that tactics such as developing a sense of rapport, urgency, and invocation of authority soften our mental defenses. On their own, these are crude tactics. The art of social engineering requires that they be combined: imposing a sense of urgency to constrain critical thinking, while invoking authority cues or loss framing to push the victim into a low-resource mental state, or building rapport subtly, increasing the feeling of connectedness until saying ‘yes’ to small requests culminates in agreeing on larger ones.
These psychological principles and processes are useful, and must be operationalized. What works on a one-to-one basis does not necessarily scale to organizational levels, where social engineers can deploy these tactics across multiple channels and divide their campaigns across many targets at once.
Making the Invisible, Visible
The best defense against social engineering is knowledge of your organization, its processes, and its people. Answering the Four T Problem in detection and response is the priority.
Review your human attack surface
Organizations are defined by their people and interpersonal trust. There is a tension between the need to trust people and channels and the need for skepticism and managing security risk. Audit cognitive and social workload by role, time of day, and business transaction types. Identify positions that have the highest workload and design controls that reduce reliance on individual judgment and reduce time pressure. Roles such as help desk, IT support, and financial operations create the widest exposed surface.
Review and communicate your policies
Security policies should be lifecycle managed, clearly communicated, and enforced. Policies are often created piecemeal in response to regulatory requirements, past incident responses, and employee feedback. Review policies together and identify gaps. Poorly communicated policies, outdated policies, and contradictions between policies leave decision points where employees default to social pressure rather than procedure.
Map out detection coverage
Use risk assessment frameworks like NIST CSF or FAIR. Identify what capabilities your organization has for detecting and responding to social engineering attempts. Focus on individual workflows and operations to identify vulnerabilities. Most organizations will find they have minimal coverage.
Know your workflows
Specific transactions belong on specific channels. Any request routed through an unexpected channel for that transaction type is not a discretionary decision left to an agent running on script. It is a detection trigger. Understanding how your workflows interact and overlap is crucial. Gaining access in one seemingly insignificant process can allow adversaries to penetrate your social network.
Maintain org chart visibility
Employees in large organizations cannot know everyone they conduct business with. Updated org charts provide a useful tool to understand reporting structures and authority. Help desk agents should be able to use them as a supplementary tool for identity verification. Ensure that these structures are concealed from external parties and treated as sensitive insider information.
Confirm explicitly
Ambiguous language or confirmation evasion in a call is a behavioral signal. Direct confirmation, verified callback through an independently registered number, and cross-checked ticket references should be procedural standards, not judgment calls made under live social pressure.
Support your people with technology
Social engineering detection requires expertise. Human experts in social engineering detection are valuable, but they are rare. Training programs cannot develop the level of expertise required to reliably detect deception, persuasion, and coercion cues that define social engineering. Adopt systems that augment your organization’s detection capacity by analyzing the conversational and behavioral signals humans cannot reliably track at scale.
What is feature engineering
In practice, feature engineering is both science and a bit of witchcraft. It often involves both iteration and experimentation to uncover hidden patterns and relationships within the data. For instance, a data scientist might transform raw sales data into features such as average purchase value, purchase frequency, or customer lifetime value, which can significantly boost the performance of a churn prediction model. By thoughtfully engineering features, practitioners can provide machine learning models with the most informative inputs, ultimately leading to better accuracy and more robust predictions.
What’s more?
- Incorporate more and more data sources
- Feature engineering platform
What is data engineering
As we mentioned above, feature engineering is certainly a subset of data engineering. It involves the ingestion of data from a source, applying a series of transformations, and making the final result available to be queried by a model for training purposes. You can construct feature engineering pipelines to resemble data engineering pipelines, having schedules, specific source and sink destinations, and availability for querying. However, this configuration would only really apply once you have surpassed the experimentation stage and determined a need for a consistent flow of new feature data.
What is feature engineering
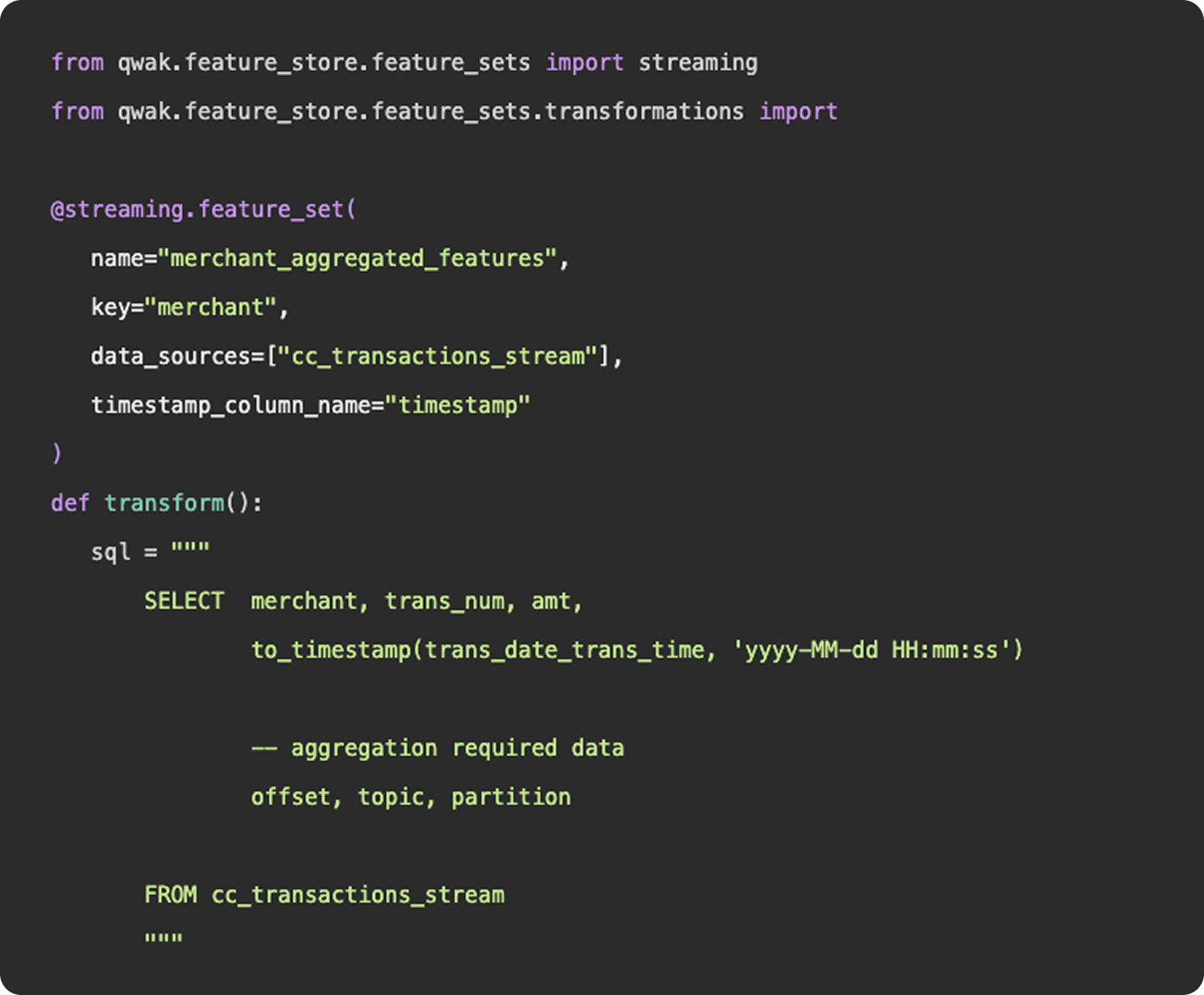
1. Functions
Functionally, there is nothing to differentiate data vs features - data points (link). Where feature engineering and data engineering really differ is in the objectives and motivations for constructing the pipelines. In general, data engineering serves a broader, more unified purpose than feature engineering. Data engineering platforms are constructed to be flexible and universal, ingesting various types and sources of data into a unified storage location where any number of transformations and use cases can be applied. The intent of a well constructed fact table or gold layer in a data lake is to provide a single source of truth that answers many different questions, produces many reports, and can be consumed by many downstream customers.
2. Practise
And in practice, an organization’s data engineering team will be responsible for the curation and maintenance of all data pipelines, not just those that relate to machine learning. These pipelines may power BI dashboards used by C-Suite, auditing reports that feed payroll, or event logs that show a user’s history of actions within the application.
Feature engineering, on the other hand, serves a specific purpose, finding the tailored inputs and columns that will generate the best predictive results for a machine learning model. Data scientists and machine learning engineers are not tasked with developing a universal data model that will ingest all data points throughout an organization, they just need to select, curate, and clean the data needed to power their models.
3. Machine learning
Now, as machine learning teams grow and begin to incorporate more and more data sources into their models, their feature engineering platform may start to resemble a larger data engineering platform in the tools and methodologies they employ. But, the intent is not to establish flexible data models that can be used throughout the organization - it is simply to power their machine learning models.
.png)