Come see us at RSAC™ 2026 Conference


[[toc]] Come see us at RSAC™ 2026 Conference
Humanix has been selected as an RSAC™ Conference Innovation Sandbox Finalist — one of the most competitive and respected recognitions in cybersecurity, awarded to a Top 10 group.
Finalists will be officially announced in an RSAC Conference press release on February 10th, followed by coverage across the security industry. The live Innovation Sandbox event takes place on March 23rd at RSAC 2026 Conference, where selected teams present their technology on stage.
RSAC Conference is the largest cybersecurity event in the world, bringing together nearly 50,000 security leaders and practitioners to discuss the most urgent challenges facing the industry.
We'll be in San Francisco throughout RSAC week, meeting with security leaders and participating in events across the conference. If you're attending RSAC 2026, we'd love to connect and share how we're approaching human-targeted attacks differently.
Innovation Sandbox Finalist
The Innovation Sandbox has a long history of spotlighting companies that go on to shape the future of cybersecurity. For over 20 years, the program has identified teams building solutions for problems the industry has not yet solved at scale.
Being selected is a strong signal that new approaches are needed, especially as modern attacks increasingly bypass technical controls and target people directly.
At RSAC Conference this year, much of the conversation will focus on how social engineering, impersonation, and human-channel attacks blend seamlessly into everyday workflows — support tickets, chat messages, voice calls, and email threads. These attacks don't look like malware. They look like normal work. That shift is exactly why the Innovation Sandbox exists.

If you're attending RSAC 2026, let's connect. We'll share how Humanix approaches human-targeted attacks and why the human layer is the most critical gap in modern security.
[[toc]] Book a meeting
What is feature engineering
In practice, feature engineering is both science and a bit of witchcraft. It often involves both iteration and experimentation to uncover hidden patterns and relationships within the data. For instance, a data scientist might transform raw sales data into features such as average purchase value, purchase frequency, or customer lifetime value, which can significantly boost the performance of a churn prediction model. By thoughtfully engineering features, practitioners can provide machine learning models with the most informative inputs, ultimately leading to better accuracy and more robust predictions.
What’s more?
- Incorporate more and more data sources
- Feature engineering platform
What is data engineering
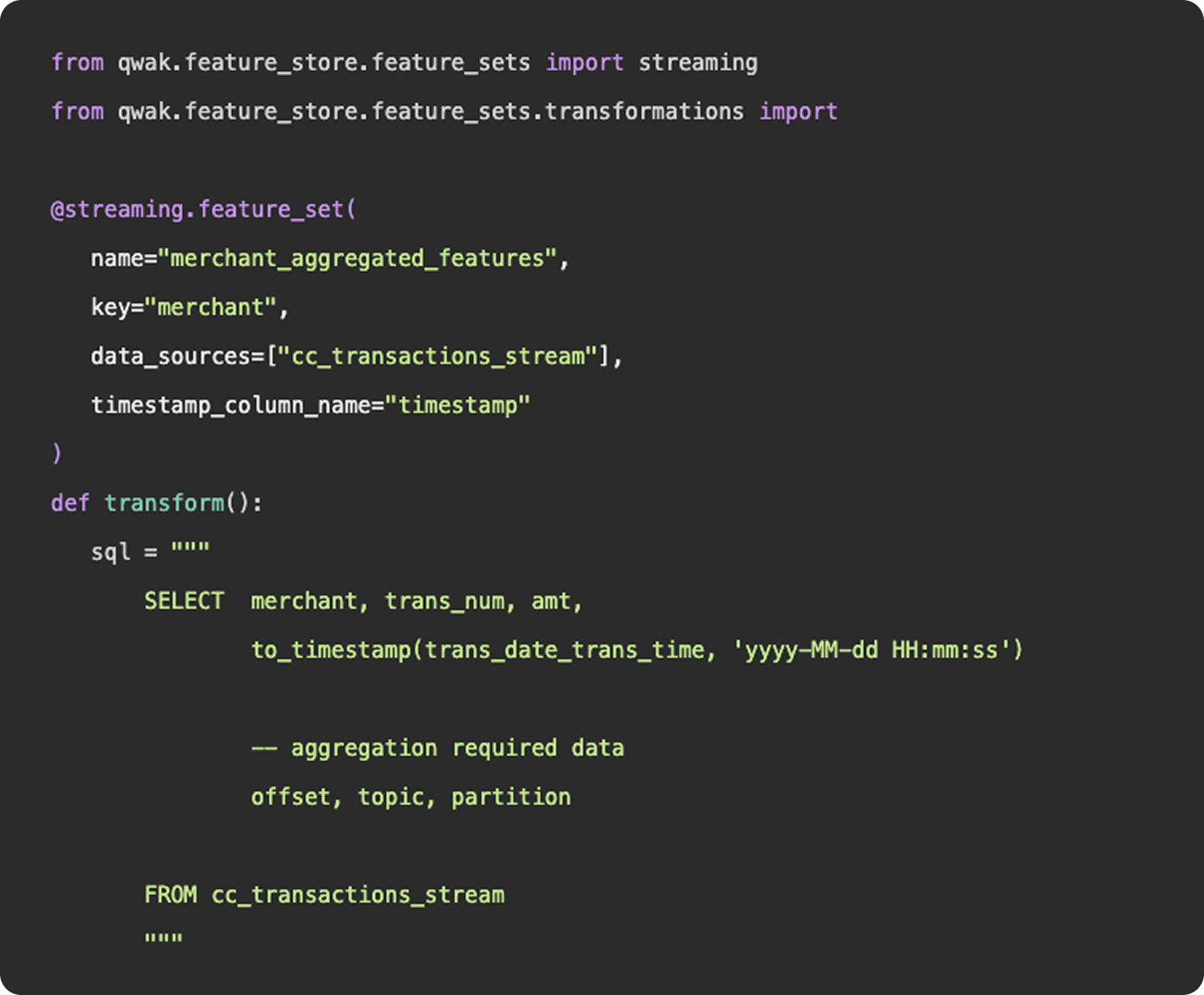
As we mentioned above, feature engineering is certainly a subset of data engineering. It involves the ingestion of data from a source, applying a series of transformations, and making the final result available to be queried by a model for training purposes. You can construct feature engineering pipelines to resemble data engineering pipelines, having schedules, specific source and sink destinations, and availability for querying. However, this configuration would only really apply once you have surpassed the experimentation stage and determined a need for a consistent flow of new feature data.
What is feature engineering
1. Functions
Functionally, there is nothing to differentiate data vs features - data points (link). Where feature engineering and data engineering really differ is in the objectives and motivations for constructing the pipelines. In general, data engineering serves a broader, more unified purpose than feature engineering. Data engineering platforms are constructed to be flexible and universal, ingesting various types and sources of data into a unified storage location where any number of transformations and use cases can be applied. The intent of a well constructed fact table or gold layer in a data lake is to provide a single source of truth that answers many different questions, produces many reports, and can be consumed by many downstream customers.
2. Practise
And in practice, an organization’s data engineering team will be responsible for the curation and maintenance of all data pipelines, not just those that relate to machine learning. These pipelines may power BI dashboards used by C-Suite, auditing reports that feed payroll, or event logs that show a user’s history of actions within the application.
Feature engineering, on the other hand, serves a specific purpose, finding the tailored inputs and columns that will generate the best predictive results for a machine learning model. Data scientists and machine learning engineers are not tasked with developing a universal data model that will ingest all data points throughout an organization, they just need to select, curate, and clean the data needed to power their models.
3. Machine learning
Now, as machine learning teams grow and begin to incorporate more and more data sources into their models, their feature engineering platform may start to resemble a larger data engineering platform in the tools and methodologies they employ. But, the intent is not to establish flexible data models that can be used throughout the organization - it is simply to power their machine learning models.